Rangos Por la Media y Desviaciones Tipicas
Por último, vamos a conocer el método correspondiente a Puntos de corte en media y desviaciones típicas seleccionadas [Fig.4-38]. Para acceder a él, debemos volver al cuadro Crear puntos de corte, haciendo clic en el botón correspondiente. Este procedimiento genera categorías basándose en los valores de la media y la desviación típica de la distribución de la variable activa.
Debemos recordar que la media es el promedio aritmético de los datos y que la desviación típica es una medida que nos informa que tan dispersos están los datos respecto al punto central (Media); desde luego este método sólo es aplicable a las variables de Escala. El procedimiento nos ofrece tres alternativas de selección +/- 1 Desv. Típica, +/- 2 Desv. Típica y +/- 3 Desv. Típica.
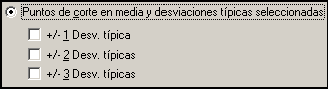
Si no se selecciona ninguna de estas opciones, el programa genera sólo dos intervalos; el primero va desde el menor valor hasta la media y el segundo desde el valor siguiente a la media hasta el máximo valor. Este método nos permite seleccionar cualquier combinación de las opciones (1 y 2, 2 y 3, 1 y 3 ó 1 2 y 3, etc.). Por cada opción que se seleccione obtendremos dos intervalos más. Por ejemplo si seleccionamos las opciones 1 y 2 obtendremos seis intervalos.
Para comprobarlo vamos a seleccionar las opciones [1 y 2] y sucesivamente hacemos clic en Aplicar de manera que los puntos de corte superiores aparecen en el histograma [Fig.4-39]. Si nos fijamos en los puntos de corte notaremos que cada uno de ellos equivale al valor de las desviaciones y el punto central equivale al valor de la media.
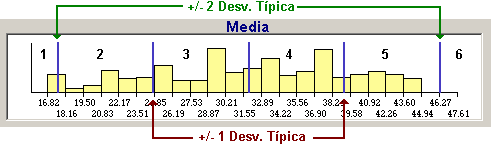
La utilidad de este método se basa en que en una distribución normal, el 68% de los casos se encuentra dentro de una distancia de una desviación típica respecto a la media, el 95% entre dos desviaciones típicas y el 99% dentro de tres desviaciones típicas. Sin embargo la creación de categorías basadas en desviaciones típicas puede ocasionar que los puntos de corte de algunas categorías queden definidos fuera del rango real de los datos, e incluso fuera del rango de valores posibles de los datos (por ejemplo, un rango de salarios negativos). Si nos fijamos en los intervalos notaremos que el primero y el último no cobijan ninguno de los casos, por lo que son obsoletos para esta variable.
Dado que el método más preciso es el de percentiles, vamos a retomarlo definiendo cuatro (4) puntos de corte superiores para los datos, de manera que obtengamos intervalos con un porcentaje aproximadamente igual para todos. Para realizarlo, debemos volver al cuadro Crear puntos de corte y definir nuevamente los cuatro puntos en la sección correspondiente (Percentiles); una vez definidos hacemos clic en Aplicar de manera que aparecen los valores 25, 30, 34, 39 y Superior en la Rejilla.
Después de definir los puntos de corte superior, es necesario introducir las etiquetas; para esta labor el procedimiento nos ofrece la opción de hacerlo en forma automática, mediante el botón Crear etiquetas. Al hacer clic en él aparecen en la columna etiquetas, las leyendas informativas de cada intervalo [Fig.4-40]. Si nos fijamos en las etiquetas, notares que el programa las genera de forma numérica y que cada intervalo incluye el valor del punto de corte superior dentro del rango.

Para finalizar con la variable Edad, sólo nos resta definirle un nombre a la nueva variable, que en nuestro caso corresponde a Edadcat. Después de definir el nombre, seleccionamos la variable categórica (Ordinal) Condición de salud (Consalud), de manera que el contenido del cuadro se actualiza y nos muestra los resultados de la exploración.
Esta variable tiene cinco diferentes categorías [Fig.4-41], las cuales pueden ser reunidas en tres. Para realizarlo, vamos a unir las categorías Buena y Relativamente buena, así como Relativamente mala y Mala, de manera que obtengamos las categorías Excelente, Buena y Mala. Si nos fijamos en el histograma de esta variable [Fig.4-42], notaremos que el valor perdido nueve (9), no aparece; esto se debe a que se definió en las propiedades de variables este valor como perdido.
Para categorizar esta variable, sólo necesitamos ingresar los puntos de corte Cero (Excelente) y 2 (Buena), con lo que obtenemos los resultados de la figura [4-43]. Si nos fijamos en las etiquetas, notaremos que el primer intervalo sólo cobija los valores Cero equivalentes a la categoría Excelente; a su vez, el segundo intervalo agrupa los valores uno y dos, correspondientes a Bueno y Relativamente bueno y el tercer intervalo (Superior), agrupa los valores tres y superiores, lo que nos indica que agrupa las categorías Relativamente mala y Mala. Para terminar debemos definir las etiquetas correctas para cada valor [Fig.4-44] y asignarle un nombre a la nueva variable que en este caso será Salud.

Después de definir las propiedades de categorización de cada una de las variables seleccionadas, hacemos clic en Aceptar con lo que parece el mensaje Las especificaciones de categorización generarán 3 variables [Fig.4-45]. Al hacer clic en Aceptar se cierra el cuadro de diálogo y las nuevas variables son creadas en el editor de datos de SPSS.
Si nos fijamos en la vista de datos del editor [Fig.4-46], notaremos que las nuevas variables apareen al final del archivo. Cada una de estas variables se define como Ordinal [Fig.4-47] y a su vez adquiere los valores perdidos que se hayan definido para la variable de origen, así mismo las etiquetas de valor definidas en el procedimiento, serán anexadas a las variables de resultados; para comprobarlo, basta con activar el botón Etiquetas en la Vista de datos.
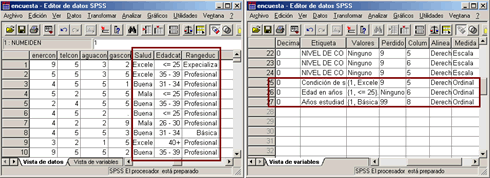
En conclusión el procedimiento Categorizador Visual, nos permite generar nuevas variables ordinales agrupando los datos de otras variables de Escala u Ordinales. Estos intervalos pueden ser creados de forma automática ya sea mediante intervalos de igual amplitud, intervalos con un porcentaje similar o mediante la media y las desviaciones típicas ó si se prefiere, se pueden definir los intervalos de acuerdo al criterio del investigador. Es necesario resaltar que este procedimiento requiere que se le definan los valores máximos de cada intervalo (Puntos de corte superior) y que a su vez, crea un número de intervalos igual al número de puntos más uno. Las variables que se generen a través del procedimiento, conservan los valores perdidos que se hayan definido para las variables originales.