Frecuencias Conjuntos de Respuesta Multiple
El módulo Base de SPSS nos ofrece dos procedimientos para el análisis descriptivo de las preguntas de respuesta múltiple (Frecuencias y Tablas de contingencia); para acceder a estos procedimientos debemos ir al menú Analizar y seleccionar el submenú Respuestas múltiples [Fig.6-34]; al desplegarse las opciones aparecen activos los procedimientos descriptivos, esto se debe a que ya se ha definido por lo menos un conjunto de variables. Para continuar con la exploración de estos procedimientos seleccionamos la opción Frecuencias con lo que aparecerá el cuadro de diálogo correspondiente [Fig.6-35].
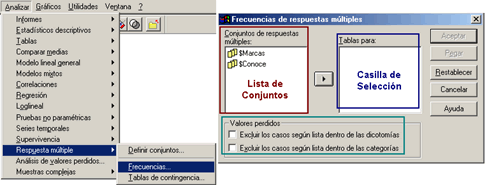
Este cuadro se encuentra dividido en tres secciones (Lista de conjuntos, casilla de selección y Valores perdidos). En la lista de conjuntos sólo aparecen los nombres de los conjuntos que se hayan definido con antelación. En la casilla de selección se deben ingresar los conjuntos a los que se desea realizar el análisis descriptivo (Tabla de frecuencias).
En la última sección (Valores perdidos) encontramos las opciones para limitar el número de casos que serán tenidos en cuenta para los cálculos, cuando se selecciona la opción Excluir los casos según lista dentro de las dicotomías el programa omitirá de los cálculos los casos que en la totalidad de las variables no tenga un valor positivo (Valor contado); es decir, excluye los casos en que aparezca una respuesta o valor diferente al número que se haya definido como valor contado dentro de los parámetros del conjunto; esta opción se suele emplear cuando se requiere una repuesta positiva en la totalidad de las preguntas.
La segunda opción corresponde a Excluir los casos según lista dentro de las categorías, al seleccionarla el programa omite los casos en los que encuentra en alguna de las variables un valor fuera del rango establecido. Además de las opciones de esta sección, el programa también omite los casos en los que no se encuentre un valor valido dentro de la totalidad de las variables (Valor contado en Dicotomías o un valor del rango en Categorías).
A manera de ejemplo vamos a generar las tablas de frecuencia para los conjuntos ($Marcas y $Conoce), por lo que debemos seleccionarlos e ingresarlos en la casilla de selección; por el momento no emplearemos las opciones de limitación de casos así que hacemos clic en Aceptar de manera que las tablas son creadas en el visor de resultados de SPSS [Fig.6-36].
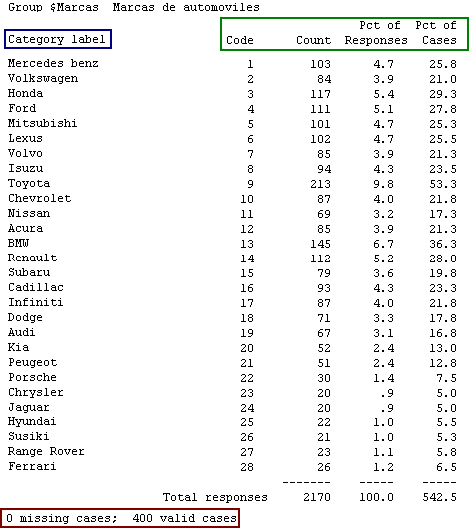
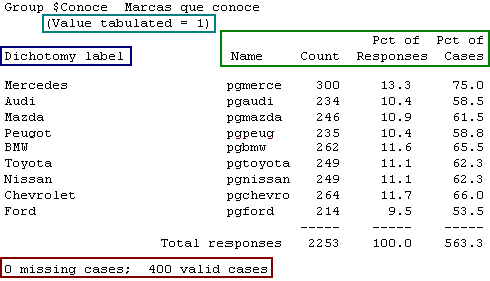
El procedimiento Frecuencias para los conjuntos de variables de respuesta múltiple, genera tablas en formato de texto, en las que se incluyen los estadísticos Recuento (Count), Porcentaje de respuestas (Pct of Responses), Porcentaje de casos (Pct of cases), Número de casos perdidos (Missing cases) y Número de casos validos (Valid cases). Para los conjuntos de categorías, los nombres de cada categoría provienen de las etiquetas de valor que se hayan definido para la primera variable del conjunto (Columna Valores en la vista de variables).
Para los conjuntos de dicotomías múltiples, los nombres de las categorías que se muestran en los resultados provienen de las etiquetas que se hayan definido para cada variable que compone el conjunto. Para facilitar la identificación del tipo de pregunta (Dicotomía o Categórica) se incluye dentro de cada tabla una leyenda en la parte superior izquierda, que nos informa el tipo de conjunto; además, cuando se trata de un conjunto de dicotomías múltiples se incluye una leyenda con el valor contado (Value Tabulated).
Si nos fijamos en los resultados de las tablas de frecuencia de la figura [6-36], notaremos que el recuento (Count) y el porcentaje de casos (Ptc of cases) cuentan con cifras bastante altas, esto se debe a que cada encuestado tiene la posibilidad de dar hasta nueve (9) respuestas para las preguntas de Dicotomías y hasta siete (7) respuestas para las preguntas Categóricas. Una de las principales dificultades de este tipo de tablas radica en la interpretación de los porcentajes; si observamos los resultados del porcentaje de casos para la marca Mercedes Benz en las dos tablas (Dicotomías y Categóricas) notaremos una amplia diferencia porcentual entre ellas, a pesar que el objetivo de los dos tipos de preguntas es identificar la aceptación o reconocimiento de las marcas en los encuestados.
Generalmente las preguntas de Dicotomías múltiples (Cerradas) tienden a mostrar porcentajes más altos debido a que el entrevistado puede ser influenciado a recordar la marca que se le pregunta, este fenómeno no se presenta en las preguntas categóricas (Abiertas) ya que no existe ningún tipo de leyenda o frase que pueda influenciar las respuestas.
Sin importar que tipo de pregunta sea, las conclusiones deben ser obtenidas de acuerdo al porcentaje de casos; por ejemplo, si asumimos que el objetivo de las dos preguntas es identificar el reconocimiento de las marcas en el mercado, de la tabla de Dicotomías múltiples concluiríamos que el 75.0% de los encuestados reconocen la marca de automóviles Mercedes Benz, mientras que de la tabla de Categóricas concluiríamos que el 25.8% de los encuestados reconoce la marca de automóviles Mercedes Benz.
Por otro lado, el porcentaje de respuestas nos indica la porción o fracción de respuestas que se puede esperar si se realizan estas mismas preguntas a otro grupo de personas, dando una orientación sobre las tendencias de las respuestas; este porcentaje no se debe tomar como una conclusión del reconocimiento de cada marca por parte de los encuestados, sino como un parámetro informativo para futuras encuestas.
A pesar que las preguntas abiertas suelen ser más confiables y precisas, no se emplean con regularidad, debido principalmente a los altos costos que implican su recolección, organización y análisis. Para finalizar con este procedimiento es necesario resaltar que los resultados de este ejemplo no son representativos del mercado ya que los datos que se incluyen en el archivo han sido manipulados a voluntad del autor, para facilitar la interpretación de los efectos del procedimiento.